

flexible and powerful open source, distributed real-time
search and analytics engine for the cloud
1. Download and unzip the latest Elasticsearch distribution.
2. Run bin/elasticsearch -f on Unix.
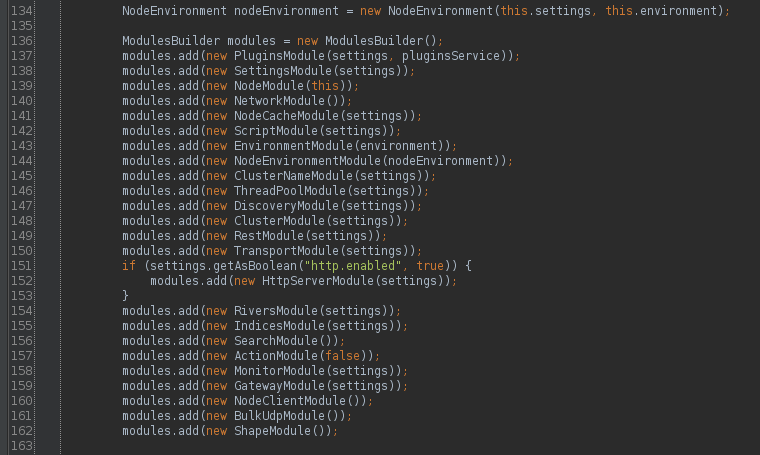 org/elasticsearch/node/internal/InternalNode.java#L136
org/elasticsearch/node/internal/InternalNode.java#L136
{
"user" : "timglabisch",
"message" : "#elasticsearch is #awesome",
"tags" : ["elasticsearch", "awesome"]
}
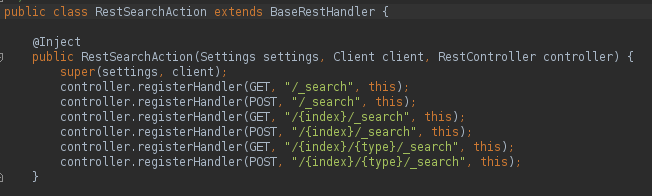 src/main/java/org/elasticsearch/rest/action/search/RestSearchAction.java#L57
src/main/java/org/elasticsearch/rest/action/search/RestSearchAction.java#L57
{
"query" : {
"term": {
"user" : "timglabisch"
}
}
}
{
"query" : {
"term": {
"user" : "timglabisch",
"message" : "#elasticsearch"
}
}
}
{
"query" : {
"term": {
"message" : "#elasticsearch"
}
}
}
- term queries use OR by default!
- know the tokenizer, there is no #elasticsearch token!
{
"query" : {
"bool": {
"must": [
{
term: {"message" : "elasticsearch" }
},
{
term: {"user" : "timglabisch" }
}
]
}
}
}
{
"query" : {
"bool": {
"must": [
{
term: {"message" : "elasticsearch" }
},
{
bool: {
"must" : {
term: {"user" : "timglabisch" }
}
}
}
]
}
}
}
- json is awesome to build queries.
- easy to write complex queries
- mix different query types
match, multi_match, bool, boosting, ids, custom_score,
custom_boost_factor, constant_score, dis_max, field, filtered, flt,flt_field,
fuzzy, has_child, has_parent, match_all, mlt, mlt_field, prefix, query_string,
range, span_first, span_near, span_not, span_or, span_term, term, terms, top_children
wildcard, nested, custom_filters_score, indices, text, geo_shape
look at the manual
{
"size": 1,
"facets" : {
"i_am_just_an_identifier": {
"terms": { "field": "source" }
}
}
}
{
"size": 1,
"facets" : {
"i_am_just_an_identifier": {
"terms": { "field": "text" }
},
"i_am_just_another_identifier": {
"terms": { "field": "source" }
}
}
}
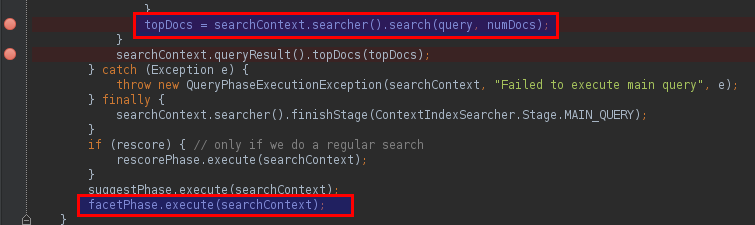 src/main/java/org/elasticsearch/search/query/QueryPhase.java#L128
src/main/java/org/elasticsearch/search/query/QueryPhase.java#L128
{
"size": 0,
"query" : {
"bool": {
"must": [
{
term: {"text" : "fuck" }
}
]
}
},
"facets" : {
"i_am_just_another_identifier": {
"terms": { "field": "source" }
},
"i_am_just_an_identifier": {
"terms": { "field": "text" }
}
}
}
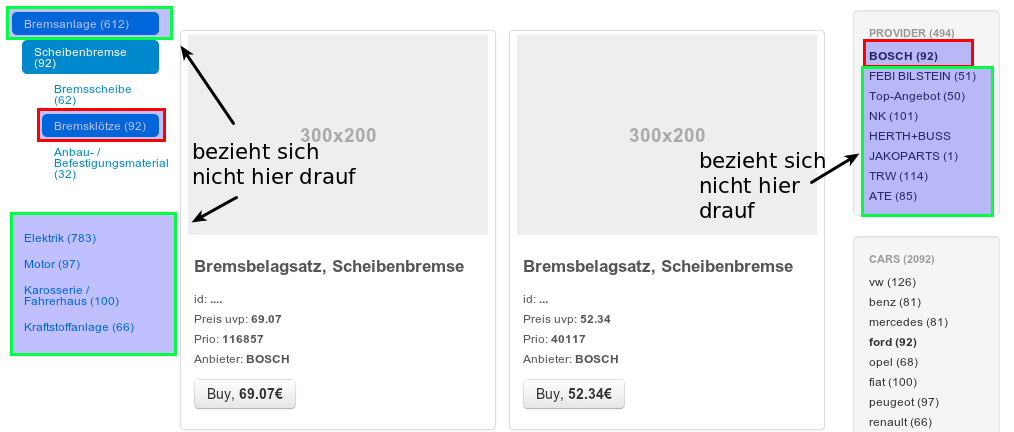
Teilabfragen können unabhängig gefiltert werden.
{
"size":16,
"facets":{
"provider":{
"terms":{
"field":"provider",
"size":35
},
"facet_filter":{
"bool":{
"must":[
{
"term":{
"level1":"Motor"
}
},
{
"term":{
"cars":"vw"
}
}
]
}
}
},
"cars":{
"terms":{
"field":"cars",
"size":35
},
"facet_filter":{
"bool":{
"must":[
{
"term":{
"level1":"Motor"
}
},
{
"term":{
"provider":"Top-Angebot"
}
}
]
}
}
},
// ....
},
"query":{
// jep we have a empty query ...
},
"filter":{
"bool":{
"must":[
{
"term":{
"level1":"Motor"
}
},
{
"term":{
"provider":"Top-Angebot"
}
},
{
"term":{
"cars":"vw"
}
}
]
}
}
}
filters are awesome flexible, cacheable and reduce the number of requests.

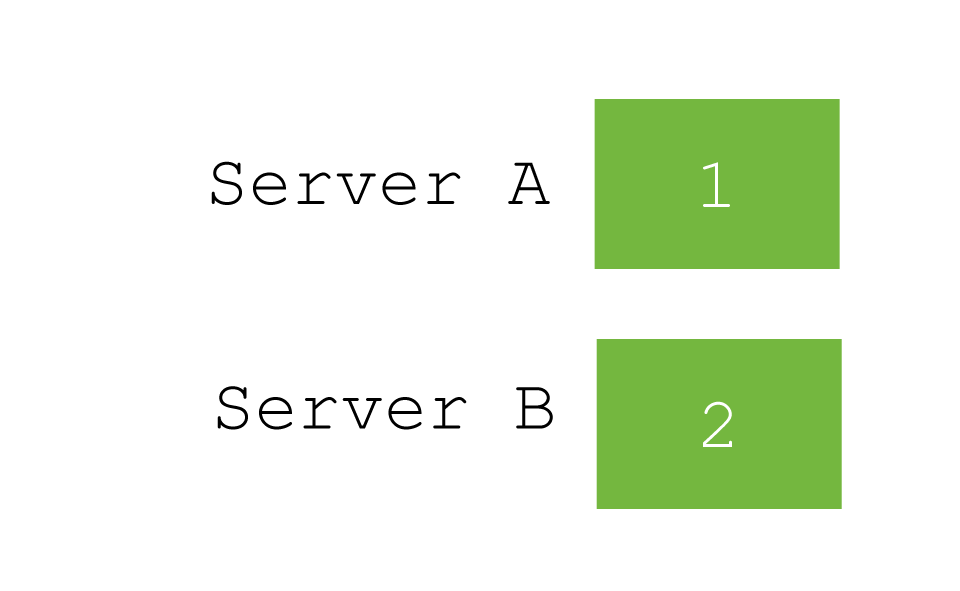
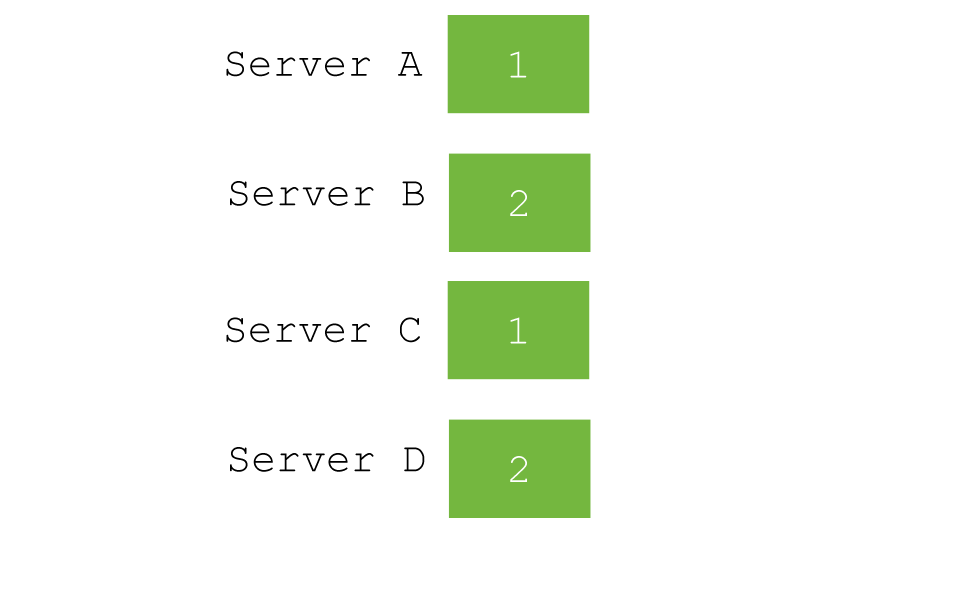
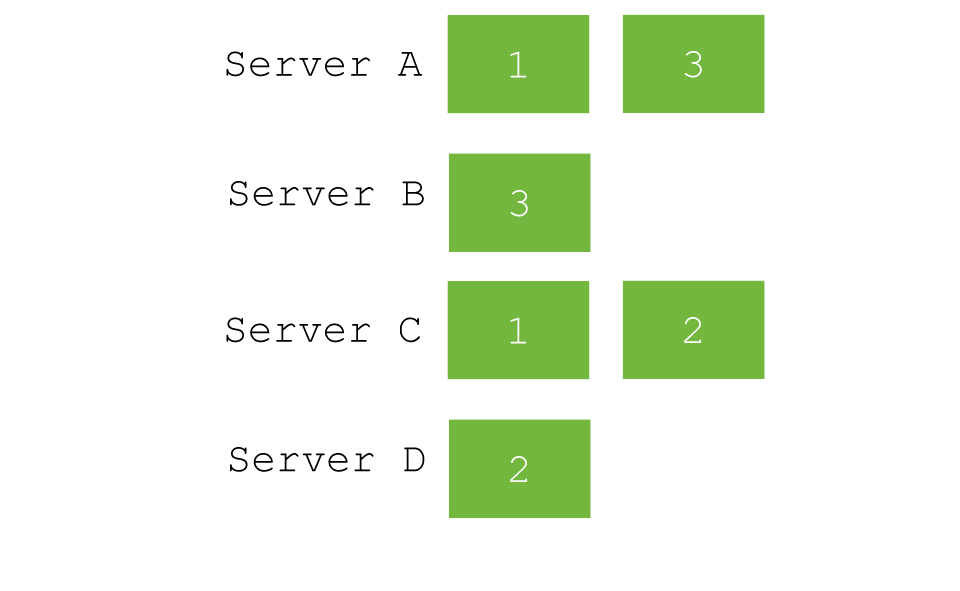
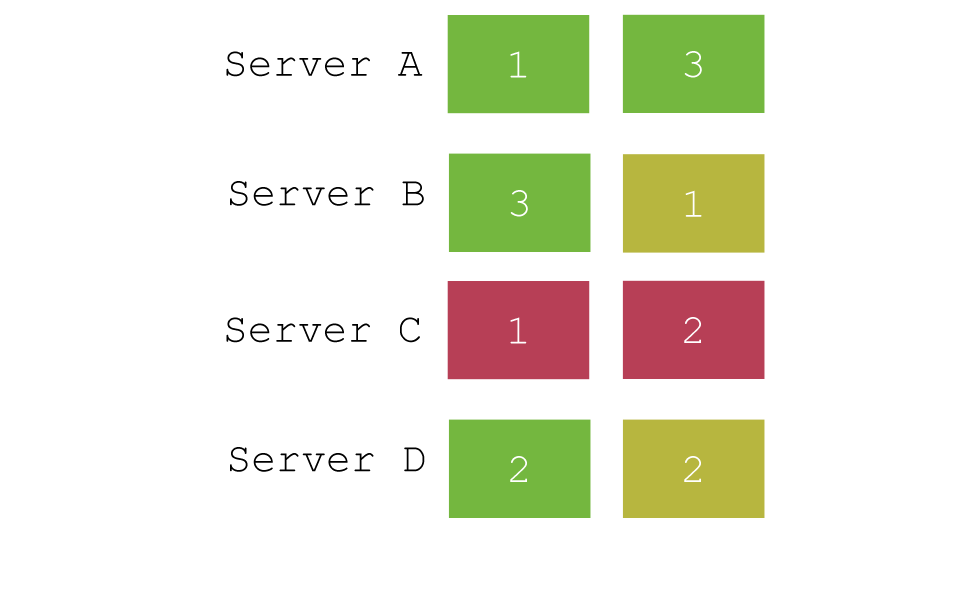
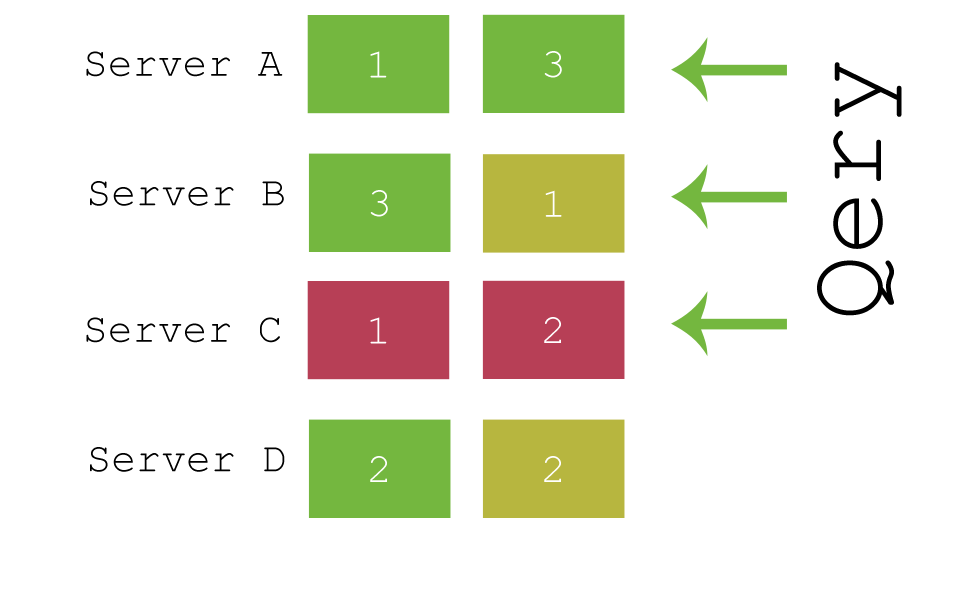
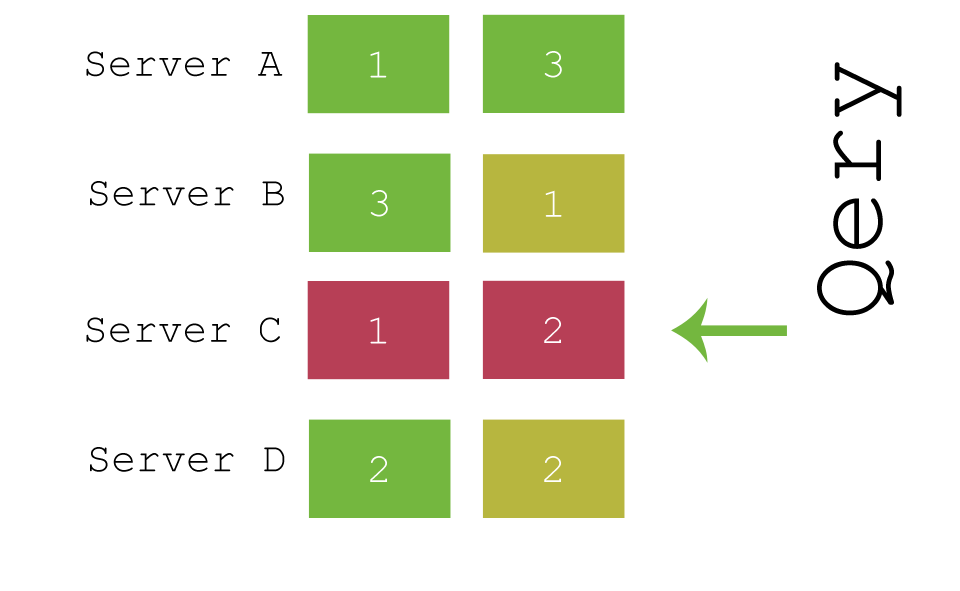
- id (default)
- parameter ( /twitter/tweet?routing=timglabisch )
- custom field / path
Elasticseatch isn't schemaless.
{
"some_value": 1
}
{
"some_value": "i am just a string"
}
sounds ugly but allows to start easy.
{
"schemaless_proof_2" : {
"properties" : {
"age" : {
"type" : "integer"
},
"name" : {
"type" : "string",
"search_analyzer": "keyword",
"index_analyzer" : "keyword"
}
}
}
}
{
"age": 4, "name" : 10
}
{
"age": 22, "name" : "Tim Glabisch"
}
 by mata.gia.rwth-aachen.de
by mata.gia.rwth-aachen.de
there are a bunch of tokenizers: Edge NGram, Keyword, Letter, Lowercase, NGram, Standard, Whitespace, Pattern, UAX URL Email, Path Hierarchy
this is a text
there are a bunch of tokenfilters: Standard, ASCII Folding, Length, Lowercase, NGram, Edge NGram, Porter Stem, Shingle, Stop, Word Delimiter, Stemmer, and 15 more...
Für die Zukunft sind
Computer mit weniger
als 1,5 Tonnen Gewicht vorstellbar.
Popular Mechanics, US-Technik-Magazin, 1949
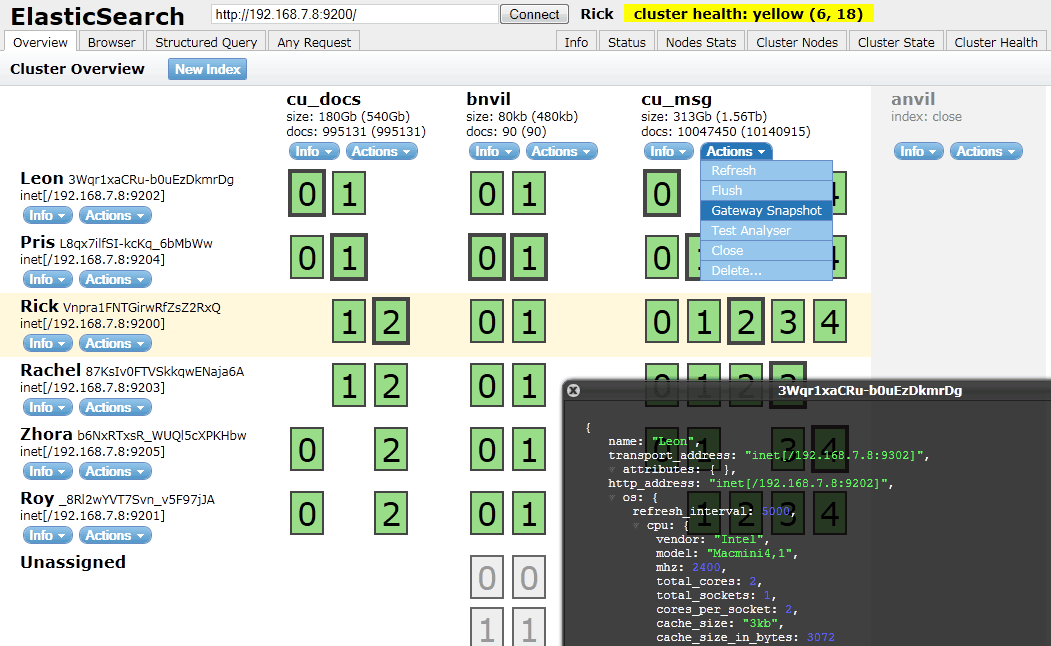
{kind=link}